pytorch(6) model (nn.Module)
Introduction
pytorch로 커스텀 모델을 만들 수 있다. 커스텀 모델을 만들기 위한 nn.Module 사용법 등을 알아본다.
Pre-question
nn.Module
nn.Module은 클래스이며 여러 기능을 모아두는 파이썬의 모듈과 비슷한 기능을 한다. 마찬가지로 다른 nn.Module도 포함할 수 있다. nn.Module 내에 어떤 것들이 들어있는지에 따라 개념적으로는 의미가 달라질 수 있다.
- 기능만 모아둘 경우 basic building block
- basic building block을 여러 개 모아둘 경우 딥러닝 모델. 간단한 custom 딥러닝 모델이 보통 이에 해당한다.
- 이 딥러닝 모델을 여러 개 모아둔 nn.Module은 대규모 딥러닝 모델이라고 할 수 있고, 좀 복잡한 모델들 (YOLOv7 등)이 이에 해당한다.
아래와 같이 add 기능을 가지는 매우 간단한 basic building block을 만들어 볼 수 있다.
import torch
from torch import nn
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x1, x2):
return torch.add(x1, x2)
__init__에서 super를 사용하는 이유
이유는 다음 링크에 잘 설명이 되어있다. 링크
- 클래스에서 인스턴스를 만들기 위해 다음과 같은 호출 과정을 거친다고 하자.
self.linear = nn.Linear(...)이 과정은 실제로는 해당 클래스(nn.Linear)의 __setattr__를 호출하는 것이다. nn.Linear는 nn.Module을 상속받았으므로, nn.Module 내의 아래가 실행된다.
def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None: # [...] modules = self.__dict__.get('_modules') if isinstance(value, Module): if modules is None: raise AttributeError("cannot assign module before Module.__init__() call") remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set) modules[name] = value여기서 modules 속성이 __init__에서 초기화되지 않을 경우 raise로 에러가 발생한다.
따라서 super로 부모클래스인 nn.Module의 __init__를 호출해 속성들을 초기화해주어야 한다.def __init__(self): """ Initializes internal Module state, shared by both nn.Module and ScriptModule. """ torch._C._log_api_usage_once("python.nn_module") self.training = True self._parameters = OrderedDict() self._buffers = OrderedDict() self._non_persistent_buffers_set = set() self._backward_hooks = OrderedDict() self._forward_hooks = OrderedDict() self._forward_pre_hooks = OrderedDict() self._state_dict_hooks = OrderedDict() self._load_state_dict_pre_hooks = OrderedDict() self._modules = OrderedDict() # <---- here
기타 getattr, setattr에 대한 내용도 참고하자. 링크
torch.nn.Sequential
torch.nn.Sequential은 모듈들을 순차적으로 실행하는 경우에 사용한다. 따라서 분기가 생기는 모델을 이 클래스로 전부 구현할 수는 없고, 순차적으로 실행되는 레이어들을 하나로 모듈화해서 사용하는 데는 유용하다. 아래는 3,2,5를 순차적으로 더하는 기능을 가진 sequential 모듈이다.
import torch
from torch import nn
class Add(nn.Module):
def __init__(self, value):
super().__init__()
self.value = value
def forward(self, x):
return x + self.value
calculator = nn.Sequential(
Add(3),
Add(2),
Add(5)
)
torch.nn.ModuleList
순차적으로 모듈을 실행하기보단, 원하는 모듈을 인덱싱해 차곡차곡 쌓아 모델을 완성하고 싶으면 사용하는 클래스이다.
class Add(nn.Module):
def __init__(self, value):
super().__init__()
self.value = value
def forward(self, x):
return x + self.value
class Calculator(nn.Module):
def __init__(self):
super().__init__()
self.add_list = nn.ModuleList([Add(2), Add(3), Add(5)])
def forward(self, x):
x = self.add_list[1](x)
x = self.add_list[0](x)
x = self.add_list[2](x)
return x
이 클래스 대신 파이썬의 list를 사용할 수도 있다. 다만 공식 문서에 따르면 nn.ModuleList를 사용할 때, 내부에 포함된 모듈들을 Module method로 접근이 가능한 장점이 있다.
ModuleList can be indexed like a regular Python list, but modules it contains are properly registered, and will be visible by all Module methods.
아래 코드를 참고한다.
class PythonList(nn.Module):
def __init__(self):
super().__init__()
# Python List
self.add_list = [Add(2), Add(3))]
def forward(self, x):
x = self.add_list[1](x)
x = self.add_list[0](x)
return x
class PyTorchList(nn.Module):
def __init__(self):
super().__init__()
# Pytorch ModuleList
self.add_list = nn.ModuleList([Add(2), Add(3)])
def forward(self, x):
x = self.add_list[1](x)
x = self.add_list[0](x)
return x
x = torch.tensor([1])
python_list = PythonList()
pytorch_list = PyTorchList()
print(python_list(x), pytorch_list(x))
print(python_list)
print(pytorch_list)
torch.nn.ModuleDict
리스트는 인덱싱을 숫자로 해야되서 불편한 점이 있다. 파이썬 dict처럼 key를 이용해 모듈을 찾아 모델을 완성하려면 nn.ModuleDict을 사용한다.
class Calculator(nn.Module):
def __init__(self):
super().__init__()
self.add_dict = nn.ModuleDict({'add2': Add(2),
'add3': Add(3),
'add5': Add(5)})
def forward(self, x):
x = self.add_dict['add3'](x)
x = self.add_dict['add2'](x)
x = self.add_dict['add5'](x)
return x
Parameter, Buffer의 사용
w, b와 같은 파라미터를 모델에 넣어줄 때 torch.tensor말고 Parameter를 써야만 gradient로 계산된 파라미터의 결과와 grad_fn이 남아있다.
Tensor를 사용하면 state_dict으로 저장된 값을 확인할 수 없다.
즉, 모델을 저장할 때 무시되기 때문에, tensor를 쓰지말고 Parameter를 쓰자.
아래는 Parameter를 쓴 모델 예시이다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Linear_Parameter(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.W = Parameter(torch.ones((out_features, in_features)))
self.b = Parameter(torch.ones(out_features))
def forward(self, x):
output = torch.addmm(self.b, x, self.W.T)
return output
x = torch.Tensor([[1, 2],
[3, 4]])
linear_parameter = Linear_Parameter(2, 3)
output_parameter = linear_parameter(x)
linear_parameter.state_dict()
register_buffer라는 것도 있는데 이것은 gradient를 계산할 필요가 없는 tensor를 값을 저장할 때 쓰인다. 관련 공식문서 설명
정리하면 다음과 같다.
- Tensor : gradient 계산안됨, 값 업데이트 안됨. 모델 저장 시 값 저장안됨.
- Buffer : 모델 저장 시 값은 저장됨.
- Paramter : 다 됨.
children vs modules
nn.module을 이용해 만든 인스턴스(모델 인스턴스)에 named_module과 named_children이 있는데 각각 모델 구조를 확인하기 위해 사용할 수 있다. 차이점은 다음과 같다.
- model.named_children() : 바로 하위 모듈까지만 표시
- model.named_modules() : 자신에게 속하는 모든 submodule을 재귀적으로 표시한다
get_submodule
하위 모듈들을 얻는 메소드인데, 아래 공식문서를 참고하자.
https://pytorch.org/docs/stable/generated/torch.nn.Module.html?highlight=get_submodule#torch.nn.Module.get_submodule
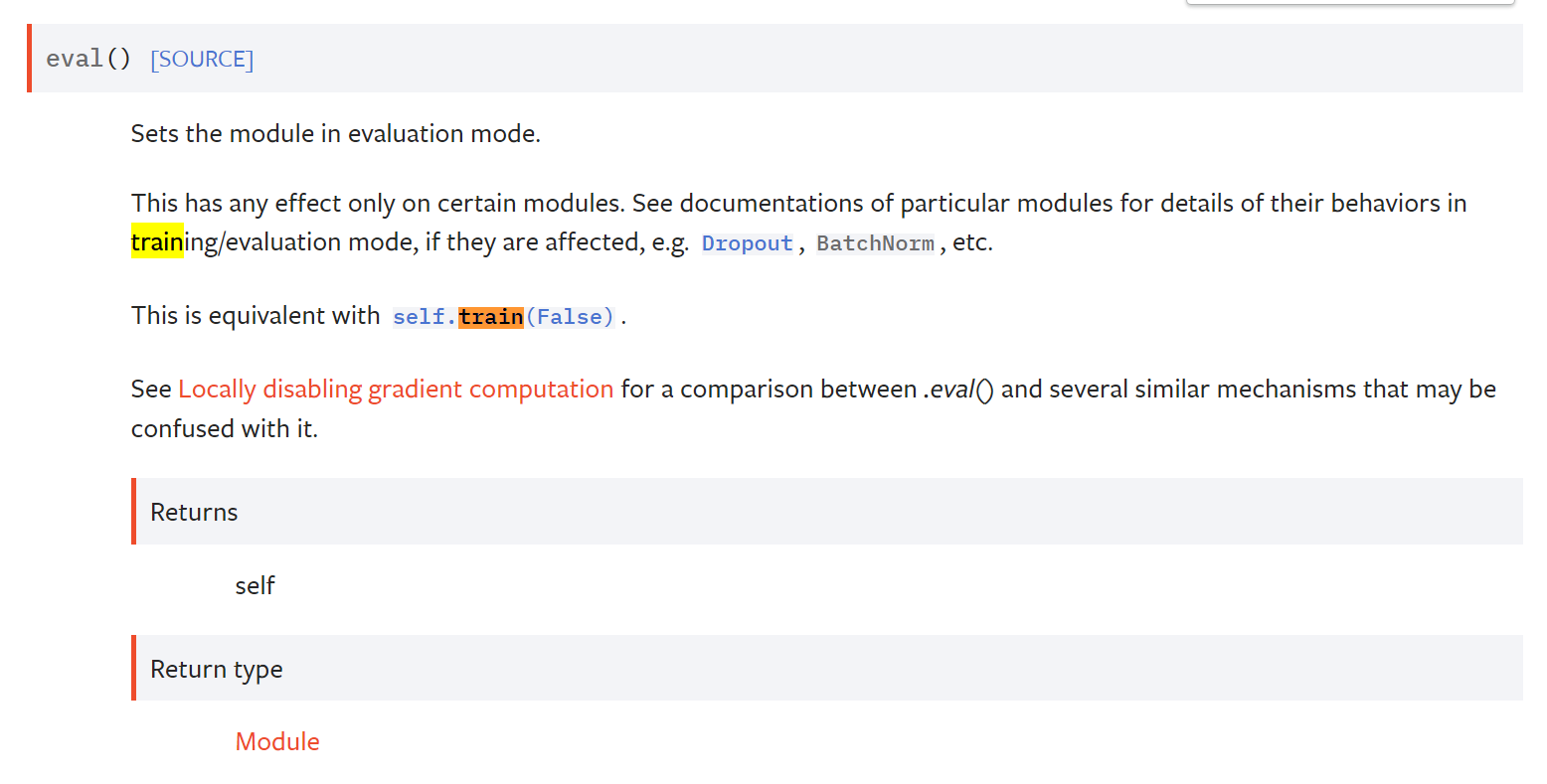
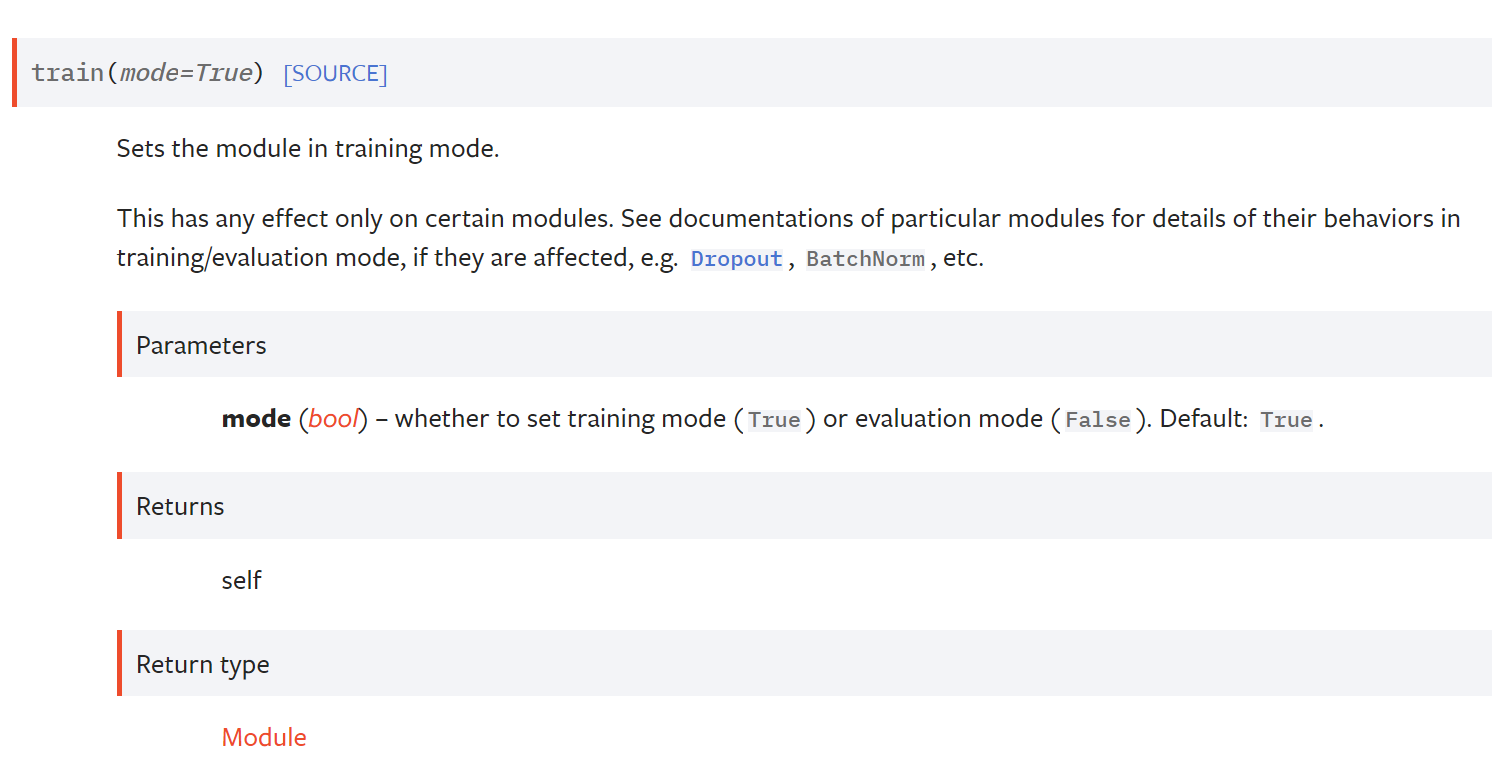
train(), eval()
nn.module의 메소드로 모델을 각각 train 모드와 evaluation 모드로 전환해주는 데 사용된다. 실제로 train, eval을 수행하는 것이 아니며, train할 때와 evalution 수행 시 다르게 처리되어야 하는 몇몇 레이어에 영향을 준다. 예를 들어 nndropout은 evaluation 시 deactivate해야 하므로 eval()을 실행하면 동작되지 않는다.
Reference
- 네이버 AI 부트캠프
- ttps://tutorials.pytorch.kr/beginner/basics/buildmodel_tutorial.html